Как распознать текст в PDF? 4 проверенных метода, которые вы можете использовать
Ключевым элементом доступности PDF-файлов является обеспечение возможности поиска по всему тексту документа. Программы чтения с экрана и другие вспомогательные технологии не могут расшифровать структуру документов, сохраненных в виде изображений, или прочитать текст с фотографий. Как распознать текст в PDF? Вы узнаете подробно о распознавании текста в PDF.
Существуют различные методы распознавания текста в PDF с помощью OnlineOCR. Гугл документыMicrosoft Word и Adobe Acrobat. Исходный документ может быть написан практически на любом языке и иметь высокое или низкое разрешение. Этими методами всегда проще сканировать документы с более высоким разрешением.
Текст из документа PDF можно автоматически распознать, извлечь и представить в текстовом формате, который легко доступен с помощью распознавания текста PDF. Следовательно, технология OCR может автоматически идентифицировать текстовые элементы в PDF-документах, экономя время на ручное транскрибирование. Узнайте, как распознавать текст в PDF, читая дальше.
См. также: Как создать PDF-файл на iPhone | 5 лучших методов, которые стоит попробовать
Что такое оптическое распознавание символов?
Оптическое распознавание символов обрабатывает отдельные страницы для создания текстовой обложки для нового документа. Следовательно, внешний вид страниц остается неизменным, когда текст, доступный для поиска, помещается под изображением страницы. 
Функциональность документа сильно ограничена, если поиск по тексту невозможен. Любая обработка текста, включая автоматическое создание закладок и связывание, извлечение и поиск текста, редактирование на основе ключевых слов и т. д., в документе запрещена. Как распознать текст в PDF? Следовательно, попробуйте использовать инструмент выделения, чтобы выделить любой текст на странице при открытии PDF-документа.
Как работает распознавание текста PDF?
Текстовые символы и другие элементы (например, графики и фотографии) в отсканированном документе можно распознать с помощью технологии OCR для распознавания текста PDF. OCR распознает отдельные символы в документе, сначала исследуя узоры светлых и темных пикселей, которые составляют специфические особенности каждого символа. Следовательно, примените эти шаблоны к уже существующим наборам правил, чтобы идентифицировать каждого персонажа. Следовательно, вы можете извлечь полезную информацию из необработанных данных, которые в противном случае были бы непригодны для использования.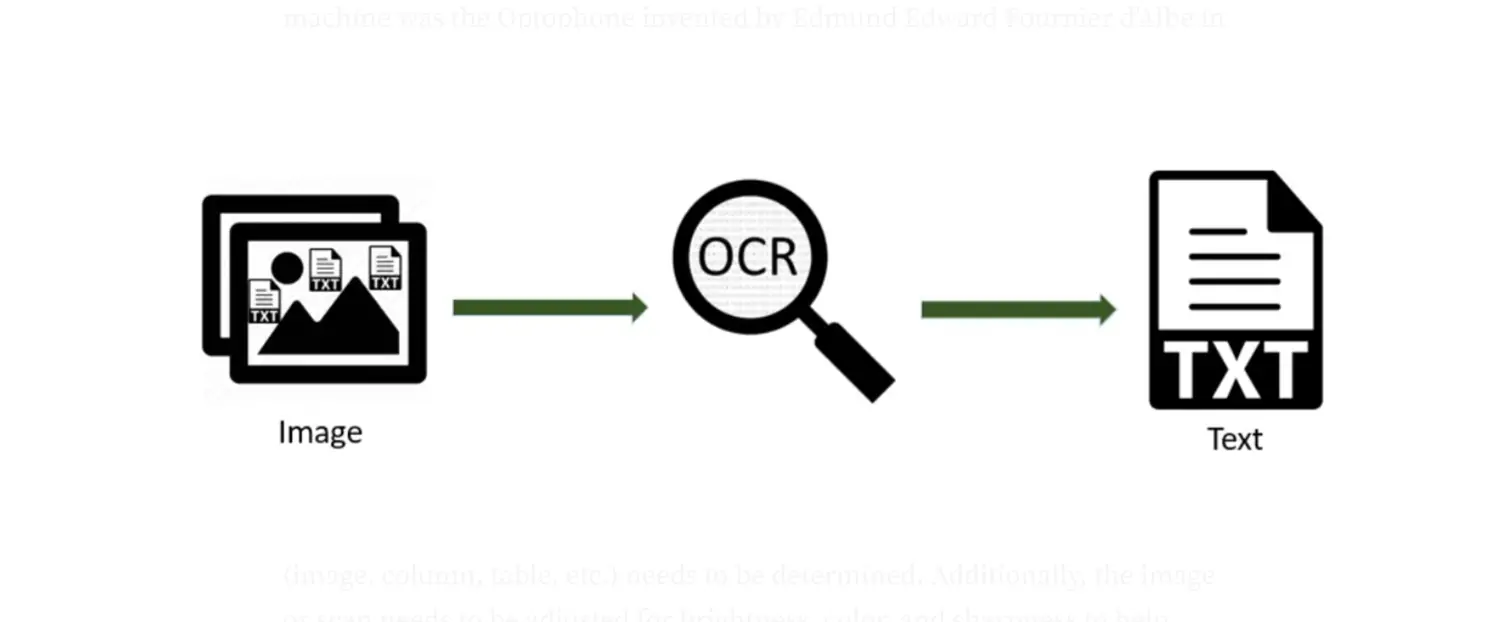
Как распознать текст в PDF? Современная технология оптического распознавания символов не ограничивается этим и может распознавать даже рукописный текст и наборы цифровых шрифтов. В прошлом технология оптического распознавания символов была относительно примитивной и для работы требовался определенный набор шрифтов.
См. Также: 14 лучших программ для распознавания лиц для Windows [Latest]
Как распознать текст в PDF?
Вы знаете, насколько это может быть сложно, если когда-либо пытались редактировать отсканированный PDF-файл или PDF-файл на основе изображения. Тем не менее, наиболее простым и практичным подходом является распознавание текста PDF. Следовательно, редактирование текста — легкая рутинная работа. Вот как распознать текст в PDF.
Использование OnlineOCR
Изображение в текст Распознавание легко осуществляется с помощью онлайн-решения OCR, такого как OnlineOCR. Таким образом, следующие шаги помогут вам в этом процессе:
- Перейдите на сайт OnlineOCR в веб-браузере.
- Обычно поиск «OnlineOCR» в предпочитаемой вами поисковой системе дает результаты.
- Нажмите «Загрузить» и выберите PDF-файл, чтобы начать распознавание текста на вашем ПК.
- Выберите язык текста в PDF.
- После выбора языка и формата вывода нажмите кнопку, например «Начать распознавание текста» или «Преобразовать», чтобы начать процесс распознавания.
- Он инициирует процесс распознавания текста в вашем PDF-файле с помощью OnlineOCR.
- Обработка PDF-файла с помощью OnlineOCR может занять некоторое время, в зависимости от размера и сложности документа.
- Проверьте вывод, чтобы убедиться, что он правильный и полный.
- Следовательно, ваш компьютер сохранит текст после выбора любимого формата для загрузки.
Использование Документов Google
Как и Word, в крайнем случае используйте Google Docs для чтения текста из PDF-документов. Многие недостатки метода Word также присутствуют в этом методе Google Docs, включая проблемы с форматированием и пространством, а также возможность лучше всего работать с PDF-файлами, которые содержат мало графики или вообще не содержат ее. Если вы ищете одни из лучших программ для аннотирования PDF-файлов для Windows, ознакомьтесь с этим.
Как распознать текст в PDF? Следовательно, использование этой процедуры позволит создать новый PDF-файл с читаемым содержимым.
- Используйте Google Диск, чтобы загрузить PDF-файл.
- Откройте PDF-файл. Чтобы открыть PDF-файл с помощью Google Docs, дважды щелкните файл.
- Нажмите «Файл» > «Сохранить как PDF» (.pdf). Теперь у вас есть PDF-файл с текстом, который вы можете распознать.
Использование Microsoft Word
Вы можете использовать Microsoft Word для идентификации текста в PDF-документе, если у вас есть к нему доступ. Обратите внимание, что основной функцией Word не является распознавание текста. Следовательно, это решение может быть безупречным. Однако этот метод лучше всего работает с PDF-файлами с небольшим количеством изображений, поскольку он подвержен ошибкам пробелов и форматирования. Следовательно, в крайнем случае этот подход может пригодиться.
Как распознать текст в PDF? Следовательно, этот метод создаст новый PDF-файл с идентифицируемым текстом вместо преобразования PDF-файла в PDF-файл с применением OCR.
- Откройте Word в Microsoft Word.
- Выберите «Обзор» в разделе «Открыть».
- Найдите и запустите PDF-файл.
- Нажмите ОК.
- Выберите «Экспорт из файла». Создайте файл XPS или PDF.
- Сохраните новый PDF-документ.
Ваш новый PDF-документ с распознаваемым текстом теперь доступен!
См. Также: Что делать, если PS4 не распознает USB?
Использование Adobe Acrobat
Как распознать текст в PDF? Adobe Reader — приложение Adobe для открытия и просмотра файлов PDF; с этим он работать не будет. Помимо огромного количества кнопок, всплывающих окон и необходимости обучения, Adobe Acrobat доступен только по подписке и для работы требует компьютера.
- Откройте Adobe Acrobat, чтобы просмотреть PDF-файл.
- Выберите Инструменты.
- Нажмите «Определить текст».
- Выберите «В этом файле».
- Нажмите ОК.
См. Также: Почему я не могу открыть PDF-файлы на своем телефоне Android?
Проблемы преобразования PDF в текст
Существует несколько препятствий, которые необходимо преодолеть при сканировании или ином преобразовании документов в PDF-файлы с возможностью поиска для преобразования исходных файлов в данные. Как распознать текст в PDF? Однако их можно использовать для обучения модели машинного обучения. 
- Одной из наиболее актуальных проблем является необходимость стандартного отсканированного документа; письмо может появляться во многих формах, размерах и формах в книгах, юридических документах, плакатах и других типах изображений с текстом. Программа OCR должна распознавать любой текст на странице.
- Исходный документ может быть практически на любом языке и в любом разрешении. В любом случае, способность распознавать текст означает, что вы понимаете не только латинский алфавит, но и множество различных систем письма.
- Сканировать высококачественные документы всегда проще. Точная идентификация всех этих символов, форм и символов с разной степенью точности — одна из проблем, которую необходимо решить OCR.
См. также: Обзор Wondershare PDFelement 9 | Использование PDF-файлов с распознаванием символов
Часто задаваемые вопросы
Почему PDF не распознает текст?
OCR может не распознать текст в PDF-файле по ряду частых причин. Решив типичные проблемы, вы сможете повысить производительность оптического распознавания символов и гарантировать более точное распознавание текста: качество изображения. Деформация текста, низкая четкость изображения и сканирование с низким разрешением — все это может повлиять на точность оптического распознавания символов.
Как работает распознавание текста?
Многие шаблоны шрифтов и текстовых изображений сохраняются в виде шаблонов с помощью базового механизма оптического распознавания символов. Здесь OCR часто сравнивает текстовые изображения с базой данных. Вы можете использовать оптическое распознавание слов, когда машина соответствует тексту слово в слово.
Почему OCR полезно?
Программное обеспечение для обработки текстов не может обрабатывать текст на фотографиях так же, как в текстовых документах. Однако технология OCR решает эту проблему. Следовательно, он преобразует текстовые изображения, которые могут исследовать дополнительные бизнес-приложения.
Каковы особенности OCR?
Обычно OCR использует открытую, масштабируемую, модульную структуру с контролем рабочего процесса. Следовательно, он может определять формы и выполнять сканирование, предварительную обработку и распознавание изображений. Технология OCR может преобразовывать распечатанные изображения персонажей в данные.
Что такое OCR-сопоставление?
Использование технологии идентификации текстовых символов внутри цифровых изображений реальных документов похоже на сканирование бумажных документов. Следовательно, это известно как отображение оптического распознавания символов (OCR).
Заключение
Речь шла о том, как распознавать текст в PDF. Поиск, копирование, вставка и выделение текста в документах PDF — одна из их наиболее ценных функций. В результате создание PDF-файла с неузнаваемым содержимым может потребовать времени и усилий, особенно если единственное другое действие — переписать весь текст. Поскольку PDF-файлы идентифицируют текст, вы можете редактировать, искать, выделять и выполнять другие операции с текстом внутри документа.
См. также: Обзор LightPDF: онлайн-конвертер PDF




![Как обойти проверку телефона Venmo? [Complete Guide]](https://20q.ru/wp-content/uploads/2023/05/how-to-bypass-venmo-phone-verification-768x416.jpg)
